@gritty said: this boss has a lot of time to speak his mind at LES, but he didn't have any time to deal with the piles of tickets
If you provided the same kind of information in ticket you provided here (so almost nothing - screenshot of panel without IP/user account/serviceID/nodename... anything that would allow VirMach to find you?) and then when he actually engaged with you and asked if that was AFTER Ryzen Migrate you ignored him and did not reply to this... what do you really expect here and why you are shocked?
@gritty said: this boss has a lot of time to speak his mind at LES, but he didn't have any time to deal with the piles of tickets
If you provided the same kind of information in ticket you provided here (so almost nothing - screenshot of panel without IP/user account/serviceID/nodename... anything that would allow VirMach to find you?) and then when he actually engaged with you and asked if that was AFTER Ryzen Migrate you ignored him and did not reply to this... what do you really expect here and why you are shocked?
i'm sorry that i can't provide more infomation, because there is no ip/node shows on control panel.
about this vps, i can find the "id=615388" in url
yes, after i pay migrate invoice, it show migrate fail. then the panel shows "virtual server not found"
that is all infomation that i can provide
Unrelated issue, looks like the node crashed and rebooted. Looking into it. Nothing to do with network, just something else happened after a reboot, maybe a bad VM powered back up that otherwise had crashed out or config change that took effect.
"Down" is the initial one on maintenance period last night, as you can see CPU got whacky afterward.
And I/O usage dropped, so it could mean something weird going on in relation to one of the disks after reboot.
I think we just need to gracefully boot people up, it's basically rebooting itself, doing everything too quickly, overloading one of the disks, overloading the server, rebooting and repeating. Changing some things now.
Okay AMSD025 should be good now, may not even require a reboot. Please keep me updated if you notice anything weird still in which case we'll have to do a reboot for some fixes to take effect.
By the way some industry news-ish that's relevant to our operation and people in Phoenix: official notice will be sent out later over the weekend once we have everything planned out, but it seems like INAP is shutting down their operation in Phoenix. I may have mentioned it earlier but have more information now, and it means we most likely have to migrate people to Las Vegas. Initially it was another DC in Phoenix but their deal fell through. Option is to get rid of Phoenix completely and move to LA, find a fifth partner that does Phoenix on short notice, or switch it over to Las Vegas and at least maintain another location around that area.
(edit) Oh god wait Las Vegas is Flex isn't it
(edit2) Sorry if this is an unprofessional update and it seems like I have no idea what we're actually doing, it's because I just found out about most of this a few minutes ago hence the unofficial update.
@VirMach said: Option is to get rid of Phoenix completely and move to LA, find a fifth partner that does Phoenix on short notice, or switch it over to Las Vegas and at least maintain another location around that area.
@VirMach said: Option is to get rid of Phoenix completely and move to LA, find a fifth partner that does Phoenix on short notice, or switch it over to Las Vegas and at least maintain another location around that area.
Just find closest xTom DC tbh :P
How I understand it is that they have a specific network blend in mind and customers who value a good connection to China so that ends up costing a lot of money in the US. We tried actually going with them in San Jose and it's definitely not within our budget in the same way Equinix network blend isn't in within our budget.
Seattle is already done. They just gave the facility to the actual owner (and worked out a deal to where people can stay.) Luckily for Seattle it's done by a company used by Microsoft and such so they know how to handle it.
Seattle is already done. They just gave the facility to the actual owner (and worked out a deal to where people can stay.) Luckily for Seattle it's done by a company used by Microsoft and such so they know how to handle it.
So weird how they're dropping facilities, I would have figured that's why they got bought since Unitas doesn't have many carrier DCs.
Seattle is already done. They just gave the facility to the actual owner (and worked out a deal to where people can stay.) Luckily for Seattle it's done by a company used by Microsoft and such so they know how to handle it.
So weird how they're dropping facilities, I would have figured that's why they got bought since Unitas doesn't have many carrier DCs.
I have no idea what INAP is doing (or rather why) but I'm sure whatever they're doing has the end goal of making sure their shareholders and executives get paid.
Emigrated there 20 years ago, got paid off after 9 months, or so (that side of the business closed down). Got offered a position in Denver with same/sister company; said "Feck that! it snows most of the year there!". Returned to chilly Scotland.
@VirMach said:
I have no idea what INAP is doing (or rather why) but I'm sure whatever they're doing has the end goal of making sure their shareholders and executives get paid.
Genuinely heartbreaking to see one of my favorite US networking companies die this way. Good news is that there's other options that are almost as good.
@FrankZ said: @YanJony - I suggest you migrate to Los Angeles if fast network speed it important to you.
This is my speed tests and ping time results for the past week from SJCZ008. Not great, but it is more or less consistently 80 Mb/s up & down which is reasonable for most uses.
This is the same time period for my VM on LAXA009 in Los Angeles which is consistently over 500 Mb/s up & down.
Definitely an issue there but also not unusable. Already reported to DC.
I don't think an upload speed of 16MBps is normal, and I know you're busy right now, so I'm patiently waiting for a fix.
@VirMach said:
I have no idea what INAP is doing (or rather why) but I'm sure whatever they're doing has the end goal of making sure their shareholders and executives get paid.
Genuinely heartbreaking to see one of my favorite US networking companies die this way. Good news is that there's other options that are almost as good.
Same for me. I've actually "known" about that for a very long time, since I was like 8 or 9 years old maybe. It's weird because it was like a "brand name" to me that I forgot about for the longest time until around maybe 2018 or 2019 when I went "INAP hmm sounds familiar they're some old internet company I remember"
@FrankZ said: @YanJony - I suggest you migrate to Los Angeles if fast network speed it important to you.
This is my speed tests and ping time results for the past week from SJCZ008. Not great, but it is more or less consistently 80 Mb/s up & down which is reasonable for most uses.
This is the same time period for my VM on LAXA009 in Los Angeles which is consistently over 500 Mb/s up & down.
Definitely an issue there but also not unusable. Already reported to DC.
I don't think an upload speed of 16MBps is normal, and I know you're busy right now, so I'm patiently waiting for a fix.
Please stop testing to Kansas, it has nothing to do with the issue that's there and that issue exists, but perhaps actually pick a server in San Jose instead of relying on their terrible geolocation partner Maxmind. They're too cheap to use good geolocation, I get it, but it doesn't mean you should only test to default server they pick.
(edit) Actually based on your test of 180Mbps to Kansas it seems like they might have finally fixed it.
@Jab said:
An hour without e-mail or notifications from HetrixTools about AMS025, seems like fixed!
Tanks!
It got fixed too well. It's actually crazy and slightly concerning because it essentially looks the same as a server where all the VMs are crashing and not working correctly but I already tested one. That's not to say it's not a possibility, but we basically went from 91% CPU to 13% CPU right now.
The extra good news is that one particular "fix" isn't yet applied to all other nodes for the most part, we discovered it recently as I spoke with someone very intelligent, much more than myself, and he basically figured out the exact problem in the background.
He doesn't want me to share the information so I'll respect his wish but basically it seems to be huge when it comes to maybe most hosts using SolusVM.
I'm just a little skeptical as it's ridiculous improvements on the host side, I just need to look more into it on the VM side.


Comments
YEAH BABY YEAH
iperf3 Network Speed Tests (IPv4): --------------------------------- Provider | Location (Link) | Send Speed | Recv Speed | | | Clouvider | London, UK (10G) | 1.87 Gbits/sec | 933 Mbits/sec Online.net | Paris, FR (10G) | 1.87 Gbits/sec | 1.61 Gbits/sec Hybula | The Netherlands (40G) | 1.88 Gbits/sec | 939 Mbits/sec Uztelecom | Tashkent, UZ (10G) | 1.72 Gbits/sec | 431 Mbits/sec Clouvider | NYC, NY, US (10G) | 1.71 Gbits/sec | 336 Mbits/sec Clouvider | Dallas, TX, US (10G) | 1.37 Gbits/sec | 162 Mbits/sec Clouvider | Los Angeles, CA, US (10G) | 1.16 Gbits/sec | 399 Mbits/secI bench YABS 24/7/365 unless it's a leap year.
back online ~5 min ago
You love to see it:
Yes sir. VirMach is definitely going in the right direction and his stuff just keeps getting better and better with time.
For staff assistance or support issues please use the helpdesk ticket system at https://support.lowendspirit.com/index.php?a=add
i'm sorry that i can't provide more infomation, because there is no ip/node shows on control panel.
about this vps, i can find the "id=615388" in url
yes, after i pay migrate invoice, it show migrate fail. then the panel shows "virtual server not found"
that is all infomation that i can provide
I mean with username & password.
AMS025 saga continues...
Haven't bought a single service in VirMach Great Ryzen 2022 - 2023 Flash Sale.
https://lowendspirit.com/uploads/editor/gi/ippw0lcmqowk.png
I can confirm.
Sorry about that one, we had a different private bridge set up on that node for something else and it interfered since it's trunk mode.
Unrelated issue, looks like the node crashed and rebooted. Looking into it. Nothing to do with network, just something else happened after a reboot, maybe a bad VM powered back up that otherwise had crashed out or config change that took effect.
"Down" is the initial one on maintenance period last night, as you can see CPU got whacky afterward.
And I/O usage dropped, so it could mean something weird going on in relation to one of the disks after reboot.
I think we just need to gracefully boot people up, it's basically rebooting itself, doing everything too quickly, overloading one of the disks, overloading the server, rebooting and repeating. Changing some things now.
Looks like it was missing one of the major updates I pushed out to all servers, adding that in as well.
Okay AMSD025 should be good now, may not even require a reboot. Please keep me updated if you notice anything weird still in which case we'll have to do a reboot for some fixes to take effect.
By the way some industry news-ish that's relevant to our operation and people in Phoenix: official notice will be sent out later over the weekend once we have everything planned out, but it seems like INAP is shutting down their operation in Phoenix. I may have mentioned it earlier but have more information now, and it means we most likely have to migrate people to Las Vegas. Initially it was another DC in Phoenix but their deal fell through. Option is to get rid of Phoenix completely and move to LA, find a fifth partner that does Phoenix on short notice, or switch it over to Las Vegas and at least maintain another location around that area.
(edit) Oh god wait Las Vegas is Flex isn't it
(edit2) Sorry if this is an unprofessional update and it seems like I have no idea what we're actually doing, it's because I just found out about most of this a few minutes ago hence the unofficial update.
You're having a bit of a 'mare, there.
Wish I was back living there, especially as tonight it's gonna approach freezing. Brrr.
Will you be taking a gamble on Las Vegas?!

It wisnae me! A big boy done it and ran away.
NVMe2G for life! until death (the end is nigh)
Just find closest xTom DC tbh :P
Haven't bought a single service in VirMach Great Ryzen 2022 - 2023 Flash Sale.
https://lowendspirit.com/uploads/editor/gi/ippw0lcmqowk.png
lol
placing bets, Seattle is next.
You're from Arizona initially?
EDIT: damn autocorrect
How I understand it is that they have a specific network blend in mind and customers who value a good connection to China so that ends up costing a lot of money in the US. We tried actually going with them in San Jose and it's definitely not within our budget in the same way Equinix network blend isn't in within our budget.
Seattle is already done. They just gave the facility to the actual owner (and worked out a deal to where people can stay.) Luckily for Seattle it's done by a company used by Microsoft and such so they know how to handle it.
lol> @VirMach said:
So weird how they're dropping facilities, I would have figured that's why they got bought since Unitas doesn't have many carrier DCs.
I have no idea what INAP is doing (or rather why) but I'm sure whatever they're doing has the end goal of making sure their shareholders and executives get paid.
Emigrated there 20 years ago, got paid off after 9 months, or so (that side of the business closed down). Got offered a position in Denver with same/sister company; said "Feck that! it snows most of the year there!". Returned to chilly Scotland.
It wisnae me! A big boy done it and ran away.
NVMe2G for life! until death (the end is nigh)
Genuinely heartbreaking to see one of my favorite US networking companies die this way. Good news is that there's other options that are almost as good.
I don't think an upload speed of 16MBps is normal, and I know you're busy right now, so I'm patiently waiting for a fix.
Speedtest by Ookla
Idle Latency: 37.89 ms (jitter: 1.38ms, low: 36.26ms, high: 39.13ms)
Download: 181.60 Mbps (data used: 110.0 MB)
318.99 ms (jitter: 67.10ms, low: 36.69ms, high: 622.17ms)
Upload: 16.45 Mbps (data used: 27.2 MB)
58.10 ms (jitter: 11.11ms, low: 37.45ms, high: 240.39ms)
Packet Loss: 0.0%
Result URL: https://www.speedtest.net/result/c/c88e81bf-fe43-4f88-b573-36de910e8099
Same for me. I've actually "known" about that for a very long time, since I was like 8 or 9 years old maybe. It's weird because it was like a "brand name" to me that I forgot about for the longest time until around maybe 2018 or 2019 when I went "INAP hmm sounds familiar they're some old internet company I remember"
Please stop testing to Kansas, it has nothing to do with the issue that's there and that issue exists, but perhaps actually pick a server in San Jose instead of relying on their terrible geolocation partner Maxmind. They're too cheap to use good geolocation, I get it, but it doesn't mean you should only test to default server they pick.
(edit) Actually based on your test of 180Mbps to Kansas it seems like they might have finally fixed it.
An hour without e-mail or notifications from HetrixTools about AMS025, seems like fixed!
Tanks!
Haven't bought a single service in VirMach Great Ryzen 2022 - 2023 Flash Sale.
https://lowendspirit.com/uploads/editor/gi/ippw0lcmqowk.png
It got fixed too well. It's actually crazy and slightly concerning because it essentially looks the same as a server where all the VMs are crashing and not working correctly but I already tested one. That's not to say it's not a possibility, but we basically went from 91% CPU to 13% CPU right now.
The extra good news is that one particular "fix" isn't yet applied to all other nodes for the most part, we discovered it recently as I spoke with someone very intelligent, much more than myself, and he basically figured out the exact problem in the background.
He doesn't want me to share the information so I'll respect his wish but basically it seems to be huge when it comes to maybe most hosts using SolusVM.
I'm just a little skeptical as it's ridiculous improvements on the host side, I just need to look more into it on the VM side.
I mean I can pinpoint the time you applied the fix!
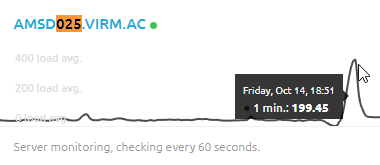
If this is working too well - no idea, I don't (yet, Sunday night attempt number 4[1]) run shit there so I can only get those ping reports ;')
[1] last time my MySQL replication did some crazy things and started running 200MB/s...
Haven't bought a single service in VirMach Great Ryzen 2022 - 2023 Flash Sale.
https://lowendspirit.com/uploads/editor/gi/ippw0lcmqowk.png