@bula said: @VirMach any hopes of getting replacement Dedicated server? Its been over 5 weeks now since the CC server shutdown.
Ref. Ticket #342867 if it helps.
Your combination of preferences has made it more difficult to fill. We can get you one if you can throw out some other potential preferences and we do have a sheet we update with the specifications and keep an eye out.
All I want is something equivalent of the hardware specs I previously had under you. If location is an issue or specs, please advice and we can go from there.
@VirMach A bit of a strange one..
I have 2 VPS on CHIZ001:
1. Small instance that's been running fine for months and still is - id=565272
2. Recently migrated from DLS and has be running fine for a week or so (previously mentioned here) but now displayed as 'Disabled' - id=630621
Not losing millions: just curiosity. If CHI is earmarked for migration, I'd have expected both VPS to be disabled.
It wisnae me! A big boy done it and ran away.
NVMe2G for life! until death (the end is nigh)
And if you've gone this far without it, honestly is the data worth all the time / money it would take to recover vs rebuilding from your last backup and going forward with it?
Also, as you have now experienced your probably first data loss it seems, welcome to the club. Please refer to standard backup thinking of 321 backups:
3 copies of your data (at least)
2 different types of media (preferable though these days that can also mean different NAS / Backup / providers)
1 of them (at least) offsite.
For example, one of my photographer friends has two different drives in his house with his client data in different parts of the house. A third copy lives at his mother in laws house like 30 min drive away in a fire proof safe, he rotates this one when he visits her with one of the ones from his house and then updates the one he brings back with any changes. And I think he also puts his original source (in this case sdcards from camera) in a bank safe deposit box. Bit more than the 321 rule but as he said, if something manages to take out all those sources of his data, it's probably because something more pressing like WW3 has broken out in which case his photo data won't be his priority anyway. Otherwise, one of the sources will survive and he can use his photos to try and recover his business.
Personally, I have two local backup servers (each has 2 drives with data) in case of a single drive failure. I also have 3 offsite backup servers on different providers (and 2 different countries even: france and US (la & nj currently)) that run every night. All of the automated routines are run via restic but there are a bunch of other options such as borg, duplicati/duplicity, etc. Restic actually has a list at https://github.com/restic/others
The other key thing is ACTUALLY CHECK YOUR BACKUPS ON A REGULAR BASIS. Far too many people setup an automated routine then never go back and check it even once, let alone on a regular basis. Stuff changes, packages can update or some required library can be updated and make your routine stop working as desired, etc.
It's one reason why I picked restic for my automated stuff, it's pretty easy to connect to the different backup endpoints as each host and look through the data, can even mount it as a local fuse directory and browse through the whole file structure, open files, etc.
Apologies if you already have something like this setup now, but I thought it might be useful for you or someone else in this situation.
@netrix said:
hey @virmach, is mass migration of LAXA014 already scheduled?
That host should be up if you need data at least. Kinda anyway (it is as I type this). Solus hadn't been able to find it for a while but my vm on it is alive and even Solus seems to recognize it currently. Try connecting via ssh & your ip even if solus says it's down.
I can give it a go, although I don't expect much given my result with strings.
And if you've gone this far without it, honestly is the data worth all the time / money it would take to recover vs rebuilding from your last backup and going forward with it?
Unfortunately between my last good backup and the disaster is >1 month and there's some important stuff in the intervening time... At the end of the day it's all worth $0 (insert "losing millions" joke here), but it's also subjectively important to me and quite a few other people.
Also, as you have now experienced your probably first data loss it seems, welcome to the club. Please refer to standard backup thinking of 321 backups:
3 copies of your data (at least)
2 different types of media (preferable though these days that can also mean different NAS / Backup / providers)
1 of them (at least) offsite.
For example, one of my photographer friends has two different drives in his house with his client data in different parts of the house. A third copy lives at his mother in laws house like 30 min drive away in a fire proof safe, he rotates this one when he visits her with one of the ones from his house and then updates the one he brings back with any changes. And I think he also puts his original source (in this case sdcards from camera) in a bank safe deposit box. Bit more than the 321 rule but as he said, if something manages to take out all those sources of his data, it's probably because something more pressing like WW3 has broken out in which case his photo data won't be his priority anyway. Otherwise, one of the sources will survive and he can use his photos to try and recover his business.
Personally, I have two local backup servers (each has 2 drives with data) in case of a single drive failure. I also have 3 offsite backup servers on different providers (and 2 different countries even: france and US (la & nj currently)) that run every night. All of the automated routines are run via restic but there are a bunch of other options such as borg, duplicati/duplicity, etc. Restic actually has a list at https://github.com/restic/others
The other key thing is ACTUALLY CHECK YOUR BACKUPS ON A REGULAR BASIS. Far too many people setup an automated routine then never go back and check it even once, let alone on a regular basis. Stuff changes, packages can update or some required library can be updated and make your routine stop working as desired, etc.
It's one reason why I picked restic for my automated stuff, it's pretty easy to connect to the different backup endpoints as each host and look through the data, can even mount it as a local fuse directory and browse through the whole file structure, open files, etc.
Apologies if you already have something like this setup now, but I thought it might be useful for you or someone else in this situation.
Thanks! One of the tragedies of this is that I "should have known better"/"knew better" but I've never had a data loss event before. Might be one of those lessons that must be learned the hard way... I was complacent, and never got an (automated!) backup procedure in place.
@Ademan said:
Thanks! One of the tragedies of this is that I "should have known better"/"knew better" but I've never had a data loss event before. Might be one of those lessons that must be learned the hard way... I was complacent, and never got an (automated!) backup procedure in place.
Automation is key; if you have to actively do something to generate your backups, then you'll forget / not get around to it just before your hardware fails. I swear drives can tell when you've been thinking "I really should do another backup..."
@Ademan said:
Thanks! One of the tragedies of this is that I "should have known better"/"knew better" but I've never had a data loss event before. Might be one of those lessons that must be learned the hard way... I was complacent, and never got an (automated!) backup procedure in place.
Yep, most people don't take it too serious until they lose something important that causes them financial or emotional distress basically.
@ahnlak said:
Automation is key; if you have to actively do something to generate your backups, then you'll forget / not get around to it just before your hardware fails. I swear drives can tell when you've been thinking "I really should do another backup..."
Yeah, by the time you think the complete sentence the hard drive has finished dying in the corner.
@bula said: @VirMach any hopes of getting replacement Dedicated server? Its been over 5 weeks now since the CC server shutdown.
Ref. Ticket #342867 if it helps.
Your combination of preferences has made it more difficult to fill. We can get you one if you can throw out some other potential preferences and we do have a sheet we update with the specifications and keep an eye out.
All I want is something equivalent of the hardware specs I previously had under you. If location is an issue or specs, please advice and we can go from there.
I don't have it pulled up in front of me but for your requirements, if the location is not a problem then reply to your ticket or confirm here and I'll make a note that it doesn't have to be the locations you specified and it'll speed it up.
nice screenplay on Tampa. Here's a Video (warning: Long-ish, @ 16 minutes of background music and text + images). Maybe a next version will have voiceovers.
I don't have it pulled up in front of me but for your requirements, if the location is not a problem then reply to your ticket or confirm here and I'll make a note that it doesn't have to be the locations you specified and it'll speed it up.
Noted VirMach, no at this point location does not matter as lone as its within USA. Please proceed with replacement Server Ref. Ticket #342867. Hope this will speed up a bit as its been over 5 weeks
I don't have it pulled up in front of me but for your requirements, if the location is not a problem then reply to your ticket or confirm here and I'll make a note that it doesn't have to be the locations you specified and it'll speed it up.
Noted VirMach, no at this point location does not matter as lone as its within USA. Please proceed with replacement Server Ref. Ticket #342867. Hope this will speed up a bit as its been over 5 weeks
The new ATLZ007B node has been stable and has greatly improved disk performance over the old ATL007 Node.
I noticed the improved performance via real world metrics so I wanted to show it for others with yabs below.
I wonder if @Virmach changed the NVMe drive type or if there is some other magic sauce that he is using to get this performance increase.
I think there is something wrong with you. The server I purchased is over 100 days old, but it is still unavailable. No one responded to the ticket sent. The picture is PAID.Ticket #362572
@H111hljone said:
I think there is something wrong with you. The server I purchased is over 100 days old, but it is still unavailable. No one responded to the ticket sent. The picture is PAID.Ticket #362572


Comments
ticket #189699 pl... thanks
blog | exploring visually |
All I want is something equivalent of the hardware specs I previously had under you. If location is an issue or specs, please advice and we can go from there.
Deranged, given the situation there, for months!
It wisnae me! A big boy done it and ran away.
NVMe2G for life! until death (the end is nigh)
hey @virmach, is mass migration of LAXA014 already scheduled?
@VirMach A bit of a strange one..
I have 2 VPS on CHIZ001:
1. Small instance that's been running fine for months and still is - id=565272
2. Recently migrated from DLS and has be running fine for a week or so (previously mentioned here) but now displayed as 'Disabled' - id=630621
Not losing millions: just curiosity. If CHI is earmarked for migration, I'd have expected both VPS to be disabled.
It wisnae me! A big boy done it and ran away.
NVMe2G for life! until death (the end is nigh)
@Ademan
Once you have a copy of the drive, have you tried running https://www.cgsecurity.org/wiki/TestDisk on it? It's one of the more common recovery programs.
And if you've gone this far without it, honestly is the data worth all the time / money it would take to recover vs rebuilding from your last backup and going forward with it?
Also, as you have now experienced your probably first data loss it seems, welcome to the club. Please refer to standard backup thinking of 321 backups:
3 copies of your data (at least)
2 different types of media (preferable though these days that can also mean different NAS / Backup / providers)
1 of them (at least) offsite.
For example, one of my photographer friends has two different drives in his house with his client data in different parts of the house. A third copy lives at his mother in laws house like 30 min drive away in a fire proof safe, he rotates this one when he visits her with one of the ones from his house and then updates the one he brings back with any changes. And I think he also puts his original source (in this case sdcards from camera) in a bank safe deposit box. Bit more than the 321 rule but as he said, if something manages to take out all those sources of his data, it's probably because something more pressing like WW3 has broken out in which case his photo data won't be his priority anyway. Otherwise, one of the sources will survive and he can use his photos to try and recover his business.
Personally, I have two local backup servers (each has 2 drives with data) in case of a single drive failure. I also have 3 offsite backup servers on different providers (and 2 different countries even: france and US (la & nj currently)) that run every night. All of the automated routines are run via restic but there are a bunch of other options such as borg, duplicati/duplicity, etc. Restic actually has a list at https://github.com/restic/others
The other key thing is ACTUALLY CHECK YOUR BACKUPS ON A REGULAR BASIS. Far too many people setup an automated routine then never go back and check it even once, let alone on a regular basis. Stuff changes, packages can update or some required library can be updated and make your routine stop working as desired, etc.
It's one reason why I picked restic for my automated stuff, it's pretty easy to connect to the different backup endpoints as each host and look through the data, can even mount it as a local fuse directory and browse through the whole file structure, open files, etc.
Apologies if you already have something like this setup now, but I thought it might be useful for you or someone else in this situation.
That host should be up if you need data at least. Kinda anyway (it is as I type this). Solus hadn't been able to find it for a while but my vm on it is alive and even Solus seems to recognize it currently. Try connecting via ssh & your ip even if solus says it's down.
Yipee! ATLZ007 is back online (last seen alive, July). It looks like it got a new 'B' node, with stuff migrated over to it.
Long may it live.
It wisnae me! A big boy done it and ran away.
NVMe2G for life! until death (the end is nigh)
Yeah mine to list as on ATLZ007B but can not boot, nor reinstall, no VNC also
@reb0rn Try using SolusVM (Control Panel)
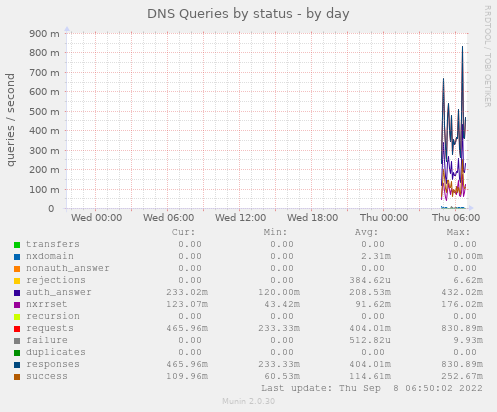
My ATLZ007B nameserver isn't even reactivated yet..
It wisnae me! A big boy done it and ran away.
NVMe2G for life! until death (the end is nigh)
same
ATLZ007B, online, thank you!")

mine ATLZ007B is also online, reconfigure network helped to make it boot
dnscry.pt - Public DNSCrypt resolvers hosted by LowEnd providers • Need a free NAT LXC? -> https://microlxc.net/
I can give it a go, although I don't expect much given my result with
strings.Unfortunately between my last good backup and the disaster is >1 month and there's some important stuff in the intervening time... At the end of the day it's all worth $0 (insert "losing millions" joke here), but it's also subjectively important to me and quite a few other people.
At the end of the day it's all worth $0 (insert "losing millions" joke here), but it's also subjectively important to me and quite a few other people.
Thanks! One of the tragedies of this is that I "should have known better"/"knew better" but I've never had a data loss event before. Might be one of those lessons that must be learned the hard way... I was complacent, and never got an (automated!) backup procedure in place.
Automation is key; if you have to actively do something to generate your backups, then you'll forget / not get around to it just before your hardware fails. I swear drives can tell when you've been thinking "I really should do another backup..."
Yep, most people don't take it too serious until they lose something important that causes them financial or emotional distress basically.
Yeah, by the time you think the complete sentence the hard drive has finished dying in the corner.
I don't have it pulled up in front of me but for your requirements, if the location is not a problem then reply to your ticket or confirm here and I'll make a note that it doesn't have to be the locations you specified and it'll speed it up.
@Virmach,
nice screenplay on Tampa. Here's a Video (warning: Long-ish, @ 16 minutes of background music and text + images). Maybe a next version will have voiceovers.
blog | exploring visually |
Noted VirMach, no at this point location does not matter as lone as its within USA. Please proceed with replacement Server Ref. Ticket #342867. Hope this will speed up a bit as its been over 5 weeks
Does 2TB work or does it have to be 2x1TB?
2TB will work
Is website design (color) updated?
TYOC035 offline. A few days(>10)
same , however, I can ping hosts under the same ip segment. It seems like my neighbors came back up but I didn't XD
Our neighbors all back.Except us.
not all, mine has been down for a while as well at TYOC035
The new ATLZ007B node has been stable and has greatly improved disk performance over the old ATL007 Node.
I noticed the improved performance via real world metrics so I wanted to show it for others with yabs below.
I wonder if @Virmach changed the NVMe drive type or if there is some other magic sauce that he is using to get this performance increase.
YABS
P.S. Thank you for removing the duplicate Tampa VM that I asked about the other day.
I think there is something wrong with you. The server I purchased is over 100 days old, but it is still unavailable. No one responded to the ticket sent. The picture is PAID.Ticket #362572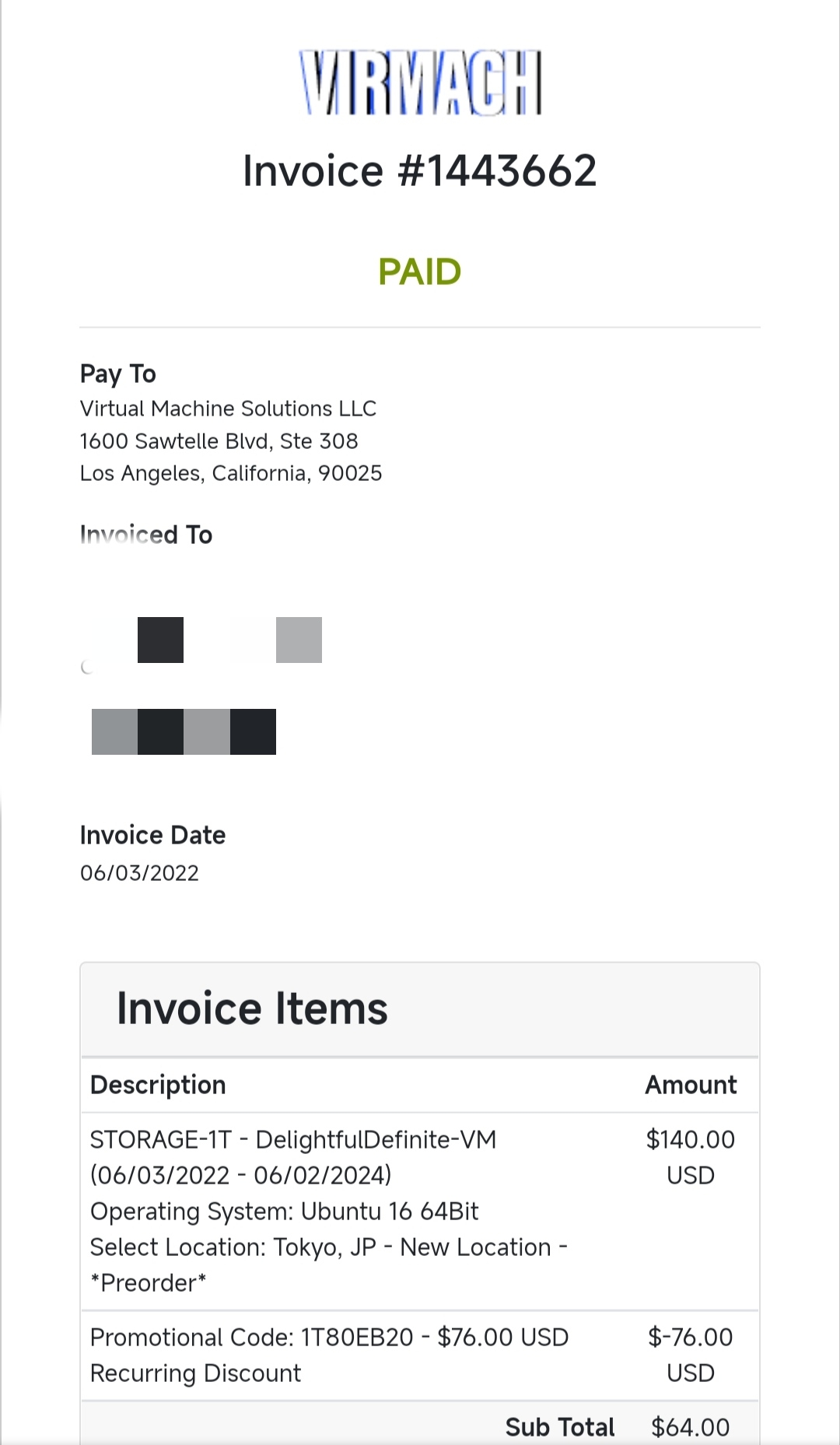
@VirMach