NYC (and slightly lesser degree AMS) has/ve been good to me. My sole CHI instance just quietly gets on with serving DNS queries.
Moral of the story: keep as far away as possible from typical Asian traffic.
TLDR: From what I've seen / experienced myself, NY & Frankfurt maybe Atlanta / Chi / Miami? Though overall summary, most locations are working at this point, having severe hardware issues that replacements are being sent out for or seem to be trying to get sorted by DC / replaced by moving to diff provider in same area. So you could go for one near your required spot and then move later when Virmach fixes it (either by beating people with rack rails into competence or moving hardware).
NYC has majority of mine currently and has been solid for myself with a few random hosts having brief issues from what I can remember for others but I don't remember seeing any others about it for a bit now.
Frankfurt had a glitch for a day or two for me and I think one other system for others but otherwise been solid for quite a while.
Dallas is busy flapping like crazy today for me and the DC inspires zero confidence, so I'll end up moving out of there until a diff provider comes in at some point I think. It's been up and down before this as well but from what I can tell by uptime stats, it's more lack of stable network than the host crashing.
Atlanta had a host (maybe two?) with issues but mine has been fine for quite a while. However, same provider as Dallas I think so yeah when shit happens, it prob won't be good.
LA has had some bad hosts and mine is borked, can't do anything Solus wise but the system itself eventually got online and has been semi stable when it's got network.
Miami & Chicago I've been on the least time so not much personal history but overall both seem to be working well from comments I've seen anyway.
SJC & Seattle I have nothing in but saw a lot of issues and attempted in person attempts by Virmach to get there due to remote hands without brains being an issue.
Everyone and their dog seems to want to be in Toyko which has caused some issues and grumblings but unless you had storage there I think everything has been online, nothing of mine is there and it's overloaded so prob won't be for now.
@Kaito said: @VirMach Just to bring this to your attention
Node: FFME001.VIRM.AC
is also one of the node which is affected by the downtime and haven't gone up/online for months, also no update about this node was published anywhere.
Please if possible, could you also give some updates about this node too if it got missed out?
I'm going to bump this up with SolusVM to try to fix these permanently but it's been a series of trying to get it stop blocking the connection to that specific node and a few others.
But I am still unable to access the vps from the time it got migrated since after the IP change I never able to get into the vps panel to atleast know the new IP, and now when I finally got the new IP, its giving connection timeout (probably offline) and no way to interact with the vps and restart (if possible) via solusvm.
So I want to ask whether I am eligible for the refund from the time this issue started which I guess around 1.5-2 months?
Note: I don't want to cancel the service, rather I just want to get the refund so I can able to extend its validity which I lost during those period.
Well..
Something's now working that didn't before. I just tried a Dallas to Chicago paid migration (no data) and it worked flawlessly and quick! Not that I particularly wanted another VPS in CHI - SEA might've been a better choice - but at least it's away from troublesome DLS.
[The 2.44 PB bandwidth might be a wee bit limiting though. ]
It wisnae me! A big boy done it and ran away.
NVMe2G for life! until death (the end is nigh)
@Daevien said:
Everyone and their dog seems to want to be in Toyko which has caused some issues and grumblings but unless you had storage there I think everything has been online, nothing of mine is there and it's overloaded so prob won't be for now.
Tokyo storage has been mostly okay through all of this too, the network hasn't been super consistent but I've had zero downtime on it since it was delivered. It's been better than my regular VPS there, I assume because there's no random virbot deal transfers or 384mb plan users on the node. I'll probably cancel or migrate my regular VPS in Tokyo, it hasn't been super useful to me, but the storage is definitely staying.
@VirMach said: I believe we've already fixed all LVM issues meaning all virtual servers should have basic functionality and only network could still have a problem.
My VPS in DALZ004 still has a corrupted /dev/vda. Per your other message, I DMed you all the info I could dig up but I will dig deeper if I can help you help me get my data back...
@bakageta said:
Tokyo storage has been mostly okay through all of this too, the network hasn't been super consistent but I've had zero downtime on it since it was delivered. It's been better than my regular VPS there, I assume because there's no random virbot deal transfers or 384mb plan users on the node. I'll probably cancel or migrate my regular VPS in Tokyo, it hasn't been super useful to me, but the storage is definitely staying.
Ah, I thought there were some issues with it. Perhaps it was a different storage location then. I don't have any storage vps with Virmach at this time so haven't been tracking it as closely.
@VirMach said: I don't know if they truly believe 40 reports in a month on a /17 IPv4 block is excessive compared to other leases.
You're looking at this wrong. You're at least 1 reseller deep into this. Cogent isn't treating each of the resellers sub clients as their own 'pool of abuse'. The reseller as a whole is grouped together for all of their leases.
You might have exactly 0 abuse on a /17, but i bet the reseller has a few /22's that are nothing but abuse, pushing his total abuse % over Cogent's limits.
As for Alibaba, I would seriously confirm what IP's you're getting. If they're just cloudinnovation space, those IP's are stolen/hijacked and at some point will be returned to AFRINIC.
@capnjb said: @virmach, DALZ009 has been unavailable since 6/27....
I believe we've already fixed all LVM issues meaning all virtual servers should have basic functionality and only network could still have a problem. We went through all connection issue - network down tickets already as well outside of maybe 4 or 5 of them and are still manually going through any remainder we detect independently where it may have an issue on our end (rare but some exist.)
"It looks like your server's networking is broken, but it should still be accessible via VNC. Try clicking the re-configure network button and wait 15 minutes. If you're still unable to connect, access your server via VNC and check the network config files for any errors. This error may also occur if you are not booted into a working operating system.
If none of the suggested solutions work, or if nothing was suggested, create a technical support ticket describing your issue. Please also provide us with your server's login info by clicking the 'add sensitive data' button so that we may access your server and investigate.
If you contact support, provide debug data:
Main IP pings: false
Node Online: true
Service online: online
Operating System:
Service Status:Active
Registration Date:2022-05-21"
No Network connectivity. I have run the network reconfigure tool many times with no joy.
As noted access via the VNC Console indicates everything but networking appears to be OK. You cannot ping the IP address nor can you ping anything but the localhost.
Latest Open Ticket #457866 all private details were provided.
This VM was working fine prior to the commencement of migration on 6/27, but has been unavailable since.
@capnjb said: I have run the network reconfigure tool many times with no joy.
The traditional 'eth0' isn't always mapped to the 'modern' equivalent..
Seeing as you haven't stated the OS: cat /proc/net/dev
or ip a
.. redact the 2nd & 3rd octect of IP addresses cat /etc/resolv.conf
and/or ip r
.. redact the 2nd/3rd octect.
If you're daft enough to use Ubuntu on a server, then nmcli connection show
or sudo nmcli -p dev status
.. might show you the actual network device.
Go into SolusVM (Control Panel) and see what IP is assigned in Network. Does it match with the above? Likely not: change it in your OS.
@capnjb said: I have run the network reconfigure tool many times with no joy.
The traditional 'eth0' isn't always mapped to the 'modern' equivalent..
Seeing as you haven't stated the OS: cat /proc/net/dev
or
@AlwaysSkint you da man! The OS is Debian 10 and the inderface was named ens3. Editing the network config fixed the problem.
Using the VNC terminal I changed eth0 to ens3 and bam! it started working. However you will see that the SolusVM in the migration tool broke it.
There is sometimes a symbolic link created at boot up, that maps ens3 to eth0. It possibly depends on exactly how the OS is installed i.e. via template or minimal ISO. The other cause of a name change could be the type of network device (VirtIO) chosen in SolusVM.
It wisnae me! A big boy done it and ran away.
NVMe2G for life! until death (the end is nigh)
^ For completeness.. Within 'dmesg' on my Linux Mint (of course!) laptop: e1000e 0000:00:19.0 enp0s25: renamed from eth0
(It's not an e1000e NIC though uses that driver.) I have seen similar elsewhere, perhaps it was CentOS - too senile to remember!
It wisnae me! A big boy done it and ran away.
NVMe2G for life! until death (the end is nigh)
@AlwaysSkint said:
^ For completeness.. Within 'dmesg' on my Linux Mint (of course!) laptop: e1000e 0000:00:19.0 enp0s25: renamed from eth0
(It's not an e1000e NIC though uses that driver.) I have seen similar elsewhere, perhaps it was CentOS - too senile to remember!
You can keep the old behavior by setting a couple flags ( primarily net.ifnames=0, biosdevname=0 for Dell hardware ). Otherwise RHEL-variants will map them to whatever is in the config file/NetworkManager file. Used to do it in udev but systemd has taken that over.
I did a $3 migration from Tampa (Node TPA-Z002) to Miami (Node MIA-Z012) on the 12th of August. After migration I ended up with two VMs in SolusVM. They were both broken, Tampa showed status "unknown" in SolusVM and would not boot. Miami showed a "No bootable device" error in VNC. After multiple attempts to fix the Miami VM myself I noted the issues on August 15th in the low priority ticket #863906 that had been automatically opened by the system at the time of migration. Toward the end of August the Tampa VM started working again. The ticket was closed in the beginning of September and can not be reopened. The Miami VM was fixed on the 4th of September. I now have the two working VMs in SolusVM, but only one (Miami) in the billing panel. I don't wish to appear to be taking advantage of you by having two working VMs but only being billed for one.
@VirMach I expect you should delete the Tampa VM on TPA-Z002 with the id #632291.
Please DO NOT delete the Miami VM on MIA-Z012 with same id #.
This action is not a priority, and I did not want to add to your ticket queue, so I am noting it here first. If you want me to open another ticket, please let me know.
@cybertech said:
which is the most stable location now?
For me Amsterdam, Denver, Frankfurt, Los Angeles, Miami, NYC, and Tokyo have all been stable and had consistent disk and network performance. I have been real happy with the VMs I have in these locations.
My problem children are in Atlanta (stability- currently down), Phoenix (network- some packet loss and high ping times), San Jose (stability/inconsistent network), Seattle (blippy network at times), Tampa (network). These VMs have not been anything to complain/ticket about but they are not as reliably consistent like the other locations I showed above.
@skorous said:
You can keep the old behavior by setting a couple flags ( primarily net.ifnames=0, biosdevname=0 for Dell hardware ). Otherwise RHEL-variants will map them to whatever is in the config file/NetworkManager file. Used to do it in udev but systemd has taken that over.
We are supposed to look forward and embrace the coolest stuff, e.g. systemd and Netplan and Docker.
Nowadays, I use Netplan to match by MAC address, regardless of NIC name. https://yoursunny.com/t/2021/Virtualizor-VNC-netplan/
@skorous said:
You can keep the old behavior by setting a couple flags ( primarily net.ifnames=0, biosdevname=0 for Dell hardware ). Otherwise RHEL-variants will map them to whatever is in the config file/NetworkManager file. Used to do it in udev but systemd has taken that over.
We are supposed to look forward and embrace the coolest stuff, e.g. systemd and Netplan and Docker.
Nowadays, I use Netplan to match by MAC address, regardless of NIC name. https://yoursunny.com/t/2021/Virtualizor-VNC-netplan/
I agree on things where looking forward makes sense like Docker and some of SystemD. I ... dislike ... Netplan. I mentioned it for mainly to help a senile old-man. Memory issues can make them agitated and it's well known that an agitated, senile Scotsman is never a good thing. ;-)
@FrankZ said: The ticket was closed in the beginning of September and can not be reopened. The Miami VM was fixed on the 4th of September. I now have the two working VMs in SolusVM, but only one (Miami) in the billing panel. I don't wish to appear to be taking advantage of you by having two working VMs but only being billed for one.
I have the same thing except Chicago and New York. I just turned off the NY one and if it doesn't get automatically cleaned up I'll ticket about it when it slows down.
@FrankZ said:
My problem children are in Atlanta (stability- currently down), Phoenix (network- some packet loss and high ping times), San Jose (stability/inconsistent network), Seattle (blippy network at times), Tampa (network). These VMs have not been anything to complain/ticket about but they are not as reliably consistent like the other locations I showed above.
Seeing the same here, Seattle is a little flakey and San Jose seems to have the most abuse (guessing best route to China) as well as some hardware issues. My current favorites are Amsterdam, Los Angeles, Chicago and NY Metro. Hoping to see more stability in those problem locations, since I have several VMs there.
@FrankZ said: The ticket was closed in the beginning of September and can not be reopened. The Miami VM was fixed on the 4th of September. I now have the two working VMs in SolusVM, but only one (Miami) in the billing panel. I don't wish to appear to be taking advantage of you by having two working VMs but only being billed for one.
I have the same thing except Chicago and New York. I just turned off the NY one and if it doesn't get automatically cleaned up I'll ticket about it when it slows down.
I shut down the Tampa one as well, but just wanted to mention it. Good to see that this is not an isolated case, as I expect that if there is enough of them VirMach will get around to cleaning them up as time allows.
@skorous said: it's well known that an agitated, senile Scotsman is never a good thing. ;-)
@cybertech said:
which is the most stable location now?
I know some people were definitely having problems (based on what was posted on LE*), but FWIW, my Tokyo VPS (TYOC036) has been working flawlessly since the NW change (no other serious problems noted before, either, however, the network was visibly worse - lower speeds and higher + somewhat unstable pings)


Comments
I concur; DALZ007 ain't much better it seems.
I've been trying to Ryzen Migrate outta there, for over a month, even though in the past it has been a good locale.
It wisnae me! A big boy done it and ran away.
NVMe2G for life! until death (the end is nigh)
blog | exploring visually |
which is the most stable location now?
I bench YABS 24/7/365 unless it's a leap year.
NYC (and slightly lesser degree AMS) has/ve been good to me. My sole CHI instance just quietly gets on with serving DNS queries.")
Moral of the story: keep as far away as possible from typical Asian traffic.
It wisnae me! A big boy done it and ran away.
NVMe2G for life! until death (the end is nigh)
TLDR: From what I've seen / experienced myself, NY & Frankfurt maybe Atlanta / Chi / Miami? Though overall summary, most locations are working at this point, having severe hardware issues that replacements are being sent out for or seem to be trying to get sorted by DC / replaced by moving to diff provider in same area. So you could go for one near your required spot and then move later when Virmach fixes it (either by beating people with rack rails into competence or moving hardware).
NYC has majority of mine currently and has been solid for myself with a few random hosts having brief issues from what I can remember for others but I don't remember seeing any others about it for a bit now.
Frankfurt had a glitch for a day or two for me and I think one other system for others but otherwise been solid for quite a while.
Dallas is busy flapping like crazy today for me and the DC inspires zero confidence, so I'll end up moving out of there until a diff provider comes in at some point I think. It's been up and down before this as well but from what I can tell by uptime stats, it's more lack of stable network than the host crashing.
Atlanta had a host (maybe two?) with issues but mine has been fine for quite a while. However, same provider as Dallas I think so yeah when shit happens, it prob won't be good.
LA has had some bad hosts and mine is borked, can't do anything Solus wise but the system itself eventually got online and has been semi stable when it's got network.
Miami & Chicago I've been on the least time so not much personal history but overall both seem to be working well from comments I've seen anyway.
SJC & Seattle I have nothing in but saw a lot of issues and attempted in person attempts by Virmach to get there due to remote hands without brains being an issue.
Everyone and their dog seems to want to be in Toyko which has caused some issues and grumblings but unless you had storage there I think everything has been online, nothing of mine is there and it's overloaded so prob won't be for now.
DALZ005 is up now, looks like network had issues but duno
Still waiting for JP storage deployment…
But I am still unable to access the vps from the time it got migrated since after the IP change I never able to get into the vps panel to atleast know the new IP, and now when I finally got the new IP, its giving connection timeout (probably offline) and no way to interact with the vps and restart (if possible) via solusvm.
So I want to ask whether I am eligible for the refund from the time this issue started which I guess around 1.5-2 months?
Note: I don't want to cancel the service, rather I just want to get the refund so I can able to extend its validity which I lost during those period.
Well..") ]
]
Something's now working that didn't before. I just tried a Dallas to Chicago paid migration (no data) and it worked flawlessly and quick! Not that I particularly wanted another VPS in CHI - SEA might've been a better choice - but at least it's away from troublesome DLS.
[The 2.44 PB bandwidth might be a wee bit limiting though.
It wisnae me! A big boy done it and ran away.
NVMe2G for life! until death (the end is nigh)
Tokyo storage has been mostly okay through all of this too, the network hasn't been super consistent but I've had zero downtime on it since it was delivered. It's been better than my regular VPS there, I assume because there's no random virbot deal transfers or 384mb plan users on the node. I'll probably cancel or migrate my regular VPS in Tokyo, it hasn't been super useful to me, but the storage is definitely staying.
My VPS in DALZ004 still has a corrupted
/dev/vda. Per your other message, I DMed you all the info I could dig up but I will dig deeper if I can help you help me get my data back...Ah, I thought there were some issues with it. Perhaps it was a different storage location then. I don't have any storage vps with Virmach at this time so haven't been tracking it as closely.
You're looking at this wrong. You're at least 1 reseller deep into this. Cogent isn't treating each of the resellers sub clients as their own 'pool of abuse'. The reseller as a whole is grouped together for all of their leases.
You might have exactly 0 abuse on a /17, but i bet the reseller has a few /22's that are nothing but abuse, pushing his total abuse % over Cogent's limits.
As for Alibaba, I would seriously confirm what IP's you're getting. If they're just cloudinnovation space, those IP's are stolen/hijacked and at some point will be returned to AFRINIC.
Francisco
"It looks like your server's networking is broken, but it should still be accessible via VNC. Try clicking the re-configure network button and wait 15 minutes. If you're still unable to connect, access your server via VNC and check the network config files for any errors. This error may also occur if you are not booted into a working operating system.
If none of the suggested solutions work, or if nothing was suggested, create a technical support ticket describing your issue. Please also provide us with your server's login info by clicking the 'add sensitive data' button so that we may access your server and investigate.
If you contact support, provide debug data:
Main IP pings: false
Node Online: true
Service online: online
Operating System:
Service Status:Active
Registration Date:2022-05-21"
No Network connectivity. I have run the network reconfigure tool many times with no joy.
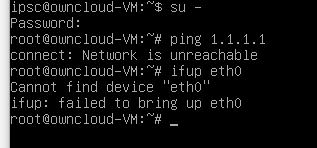
As noted access via the VNC Console indicates everything but networking appears to be OK. You cannot ping the IP address nor can you ping anything but the localhost.
Latest Open Ticket #457866 all private details were provided.
This VM was working fine prior to the commencement of migration on 6/27, but has been unavailable since.
Regards,
Jon
The traditional 'eth0' isn't always mapped to the 'modern' equivalent..
Seeing as you haven't stated the OS:
cat /proc/net/devor
ip a.. redact the 2nd & 3rd octect of IP addresses
cat /etc/resolv.confand/or
ip r.. redact the 2nd/3rd octect.
If you're daft enough to use Ubuntu on a server, then
nmcli connection showor
sudo nmcli -p dev status.. might show you the actual network device.
Go into SolusVM (Control Panel) and see what IP is assigned in Network. Does it match with the above? Likely not: change it in your OS.
It wisnae me! A big boy done it and ran away.
NVMe2G for life! until death (the end is nigh)
@AlwaysSkint
@AlwaysSkint you da man! The OS is Debian 10 and the inderface was named ens3. Editing the network config fixed the problem.
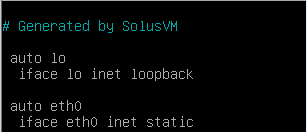
Using the VNC terminal I changed eth0 to ens3 and bam! it started working. However you will see that the SolusVM in the migration tool broke it.
Thank you so much!
Regards,
capnjb
There is sometimes a symbolic link created at boot up, that maps ens3 to eth0. It possibly depends on exactly how the OS is installed i.e. via template or minimal ISO. The other cause of a name change could be the type of network device (VirtIO) chosen in SolusVM.
It wisnae me! A big boy done it and ran away.
NVMe2G for life! until death (the end is nigh)
^ For completeness.. Within 'dmesg' on my Linux Mint (of course!) laptop:
e1000e 0000:00:19.0 enp0s25: renamed from eth0(It's not an e1000e NIC though uses that driver.) I have seen similar elsewhere, perhaps it was CentOS - too senile to remember!
It wisnae me! A big boy done it and ran away.
NVMe2G for life! until death (the end is nigh)
You can keep the old behavior by setting a couple flags ( primarily net.ifnames=0, biosdevname=0 for Dell hardware ). Otherwise RHEL-variants will map them to whatever is in the config file/NetworkManager file. Used to do it in udev but systemd has taken that over.
I did a $3 migration from Tampa (Node TPA-Z002) to Miami (Node MIA-Z012) on the 12th of August. After migration I ended up with two VMs in SolusVM. They were both broken, Tampa showed status "unknown" in SolusVM and would not boot. Miami showed a "No bootable device" error in VNC. After multiple attempts to fix the Miami VM myself I noted the issues on August 15th in the low priority ticket #863906 that had been automatically opened by the system at the time of migration. Toward the end of August the Tampa VM started working again. The ticket was closed in the beginning of September and can not be reopened. The Miami VM was fixed on the 4th of September. I now have the two working VMs in SolusVM, but only one (Miami) in the billing panel. I don't wish to appear to be taking advantage of you by having two working VMs but only being billed for one.
@VirMach I expect you should delete the Tampa VM on TPA-Z002 with the id #632291.
Please DO NOT delete the Miami VM on MIA-Z012 with same id #.
This action is not a priority, and I did not want to add to your ticket queue, so I am noting it here first. If you want me to open another ticket, please let me know.
For me Amsterdam, Denver, Frankfurt, Los Angeles, Miami, NYC, and Tokyo have all been stable and had consistent disk and network performance. I have been real happy with the VMs I have in these locations.
My problem children are in Atlanta (stability- currently down), Phoenix (network- some packet loss and high ping times), San Jose (stability/inconsistent network), Seattle (blippy network at times), Tampa (network). These VMs have not been anything to complain/ticket about but they are not as reliably consistent like the other locations I showed above.
We are supposed to look forward and embrace the coolest stuff, e.g. systemd and Netplan and Docker.
Nowadays, I use Netplan to match by MAC address, regardless of NIC name.
https://yoursunny.com/t/2021/Virtualizor-VNC-netplan/
No hostname left!
Hello push-up specialist,
The latest incident has been resolved and your monitor is up again. Good job!
Monitor name: vps7 VirMach ATL
Checked URL: 149.57.204.x
Root cause: Host Is Unreachable
Incident started at: 2022-09-04 09:07:31
Resolved at: 2022-09-06 04:00:53
Duration: 42 hours and 53 minutes
ATLZ010 is resurrected.
Ticket will remain open until system delivers SLA credit.
No hostname left!
Migration auto-credit working here... Failed to move one of my Dallas VPS to Miami :-) ... 3 automated tickets wasted xD
I agree on things where looking forward makes sense like Docker and some of SystemD. I ... dislike ... Netplan. I mentioned it for mainly to help a senile old-man. Memory issues can make them agitated and it's well known that an agitated, senile Scotsman is never a good thing. ;-)
I have the same thing except Chicago and New York. I just turned off the NY one and if it doesn't get automatically cleaned up I'll ticket about it when it slows down.
Seeing the same here, Seattle is a little flakey and San Jose seems to have the most abuse (guessing best route to China) as well as some hardware issues. My current favorites are Amsterdam, Los Angeles, Chicago and NY Metro. Hoping to see more stability in those problem locations, since I have several VMs there.
I shut down the Tampa one as well, but just wanted to mention it. Good to see that this is not an isolated case, as I expect that if there is enough of them VirMach will get around to cleaning them up as time allows.
^ Whaur's ma bloody sporran gone, the noo!
It wisnae me! A big boy done it and ran away.
NVMe2G for life! until death (the end is nigh)
I know some people were definitely having problems (based on what was posted on LE*), but FWIW, my Tokyo VPS (TYOC036) has been working flawlessly since the NW change (no other serious problems noted before, either, however, the network was visibly worse - lower speeds and higher + somewhat unstable pings)
Contribute your idling VPS/dedi (link), Android (link) or iOS (link) devices to medical research
virrrMMMAAAcchhHHH where is my refund